
The question of how to remove pages from google’s index has popped up twice in conversations with SEO clients in the last couple of days (perhaps fulled by the post Panda 4.0 panic…).
The process is pretty straight forward, but one that often causes confusion and is surprisingly easy to mess up.
Here is how to do it right and (importantly) to make sure that the pages you have removed don’t come back!
But first…
Why Would You Want To Remove Pages From Google’s Index?
Basically, since google Panda, having lots of ‘thin’ or duplicate content pages on your site can cause problems.
Before Panda if a page was low quality it just wouldn’t be indexed or ranked, but since Panda too many thin pages can cause your whole site to be penalised and lose it’s rankings.
I’m not going to go into too much detail here on what makes content ‘thin’ (you might want to read my post on duplicate content problems and solutions), but some quick examples of the types of content that you want to look out for are: –
- Search pages
- Add review pages
- Product sort pages
- Blog archive pages
Ask yourself honestly ‘does this page deserve to be indexed by google/rank?’
If the answer is no, then get it out of the index.
A lean, mean site with 100 quality pages will perform much better (and by that I mean bring in organic search traffic) than a bloated 10,000 page gorilla full of unnecessary pages.
Checking Your Site For Thin Content
It’s pretty straight forward to find out what google is currently indexing on your site.
You can do this by typing in the following query to a google search: –
site:www.yoursite.com
If I search Top 5 SEO for example, google tells me that it currently has 109 indexed pages.
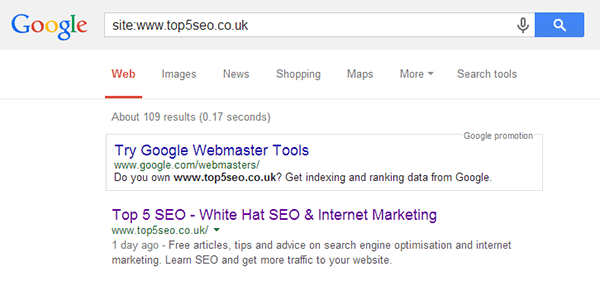
- There are currently 88 published posts on this site, so along with the category pages etc that sounds about right.
- If the figure had been 209 then I would probably want to take a closer look to see what was being indexed.
- If the figure was 2000, then I would definitely want to take a closer look!
This is of course a relatively small site (in terms of number of pages!), so if you have a larger site then it might take a little while to look through what is indexed and work out whether it should be there or not – but it will be time well spent.
So once you have identified content to be removed from google, how do you go about removing it?
[signup]I Just Block The Pages In Robots.txt Right?
This is a mistake that many people make.
Blocking a directory (i.e. /search/) in robots.txt is part of the process (and I will cover it later), but it is actually the final step and not the first.
Blocking robots from visiting certain directories will just mean that they cannot recrawl the page (it doesn’t specifically tell them to remove them) and you may well end up with old, expired, thin urls just sitting rotting away in the index (and dragging down your site) until the end of time.
So what is the first step?
Page Removal Step 1: Set Robots Meta Tag To Noindex, Follow
The first step in removing a page from google’s index is to add the robots meta tag and set it up so that your site instructs a visiting spider not to index the page, but to follow any links contained on it.
The tag looks like this and should be inserted into the <head> section of the page: –
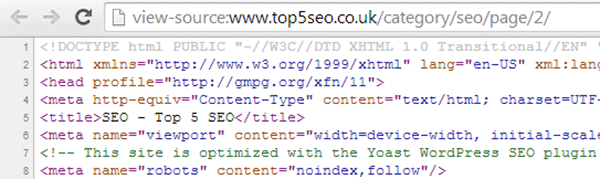
<meta name=”robots” content=”noindex, follow”>
In theory, the default action of a search spider should be to follow all links anyway, but I normally add in ‘follow’ just to make sure.
I have the noindex tag inserted into the archive pages on my blog (other than the first page). So for example, if we look at the source for the SEO category page 2, you can see the tag on line 8: –
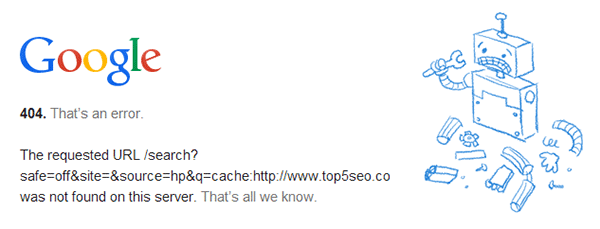
A quick search (cache:https://top5seo.co.uk/category/seo/page/2/) confirms that google is complying with the request not to index the page.
Adding the robots tag should be your first step, but the page won’t be removed from the index until it is next crawled. So how can you expedite the process?
Page Removal Step 2: Expedite The Process By Using Webmaster Tools To Remove By Directory
If you have the time you can use webmaster tools go through URL by URL and expedite the removal process. Certainly what you should do is remove any directory specific duplicate/thin content problems as this is easy to do.
For example you can remove anything with the path yourdomain.com/search/ with one request.
Here’s how you do it!
- Log into webmaster tools and click Google Index > Remove URLs > Create A New Removal Request
- Enter the directory you want to remove, i.e. yourdomain.com/search and then click continue
- Select ‘Remove Directory’ from the drop down box and then click ‘Submit Request’
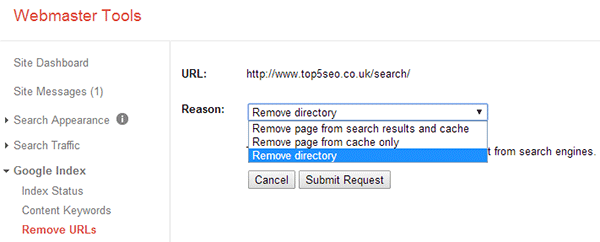
Google should then remove everything under that path from it’s index.
To remove a specific page just enter the url and select ‘Remove page from search results and cache’.
The robots tag in step 1 will ensure that nothing is reindexed, but just to be sure…
Page Removal Step 3: Block The Directory In Robots.txt
Important: Do not complete this step until the pages have been removed from the index. You can use the site: command again in google to make sure all the content has been removed, i.e.
site:yourdomain.com/search/
Once it has gone, you can now use robots.txt to stop anything in the directory from being crawled in the future.
So, to block the yourdomain/search path you would add the following rule to your robots.txt file: –
User-agent: *
Disallow: /search/
User-agent all means the instruction is for all robots (spiders) and disallow means that the robot should not crawl any content in that directory.
You can use the blocked URLs tool in google webmaster tools (Crawl > Blocked URLs) to verify that the rule is working correctly.
And That Is That!
So, that’s the process of removing pages from google and making sure they stay gone. Easy right?
With the release of Panda 4.0 this week, it’s well worth running through this process and getting any unnecessary pages on your site out of the index.
Any questions, just leave a comment below and for loads more actionable white hat SEO tutorials, sign up to our free newsletter below!
[bigsignup]